Kandidat — j'avais besoin d'un outil de suivi de candidatures, je l'ai conçu et déployé avec une approche DevOps
Le point de départ : chercher un poste en Guadeloupe
Quand on cherche un emploi en Guadeloupe dans le domaine du DevOps, le marché est étroit. Les offres locales se comptent sur les doigts d’une main, alors il faut jongler entre les quelques postes sur place, les opportunités en remote, et les candidatures spontanées. Chaque piste compte, et c’est justement pour ça qu’il faut être structuré : ne rien laisser passer, relancer au bon moment, adapter son CV à chaque contexte. Mes notes ne suffisaient plus.
J’avais besoin d’un outil qui centralise tout : les candidatures, les entreprises ciblées, les contacts, les fichiers joints, et surtout qui m’aide à adapter mon CV à chaque poste. Plutôt que de chercher un énième SaaS, j’ai décidé de le concevoir moi-même, de le réaliser avec le support de Claude Code, et d’automatiser son déploiement sur mon homelab en mettant en pratique la culture DevOps que j’applique au quotidien.
C’est comme ça que Kandidat est né.
Ce que fait Kandidat
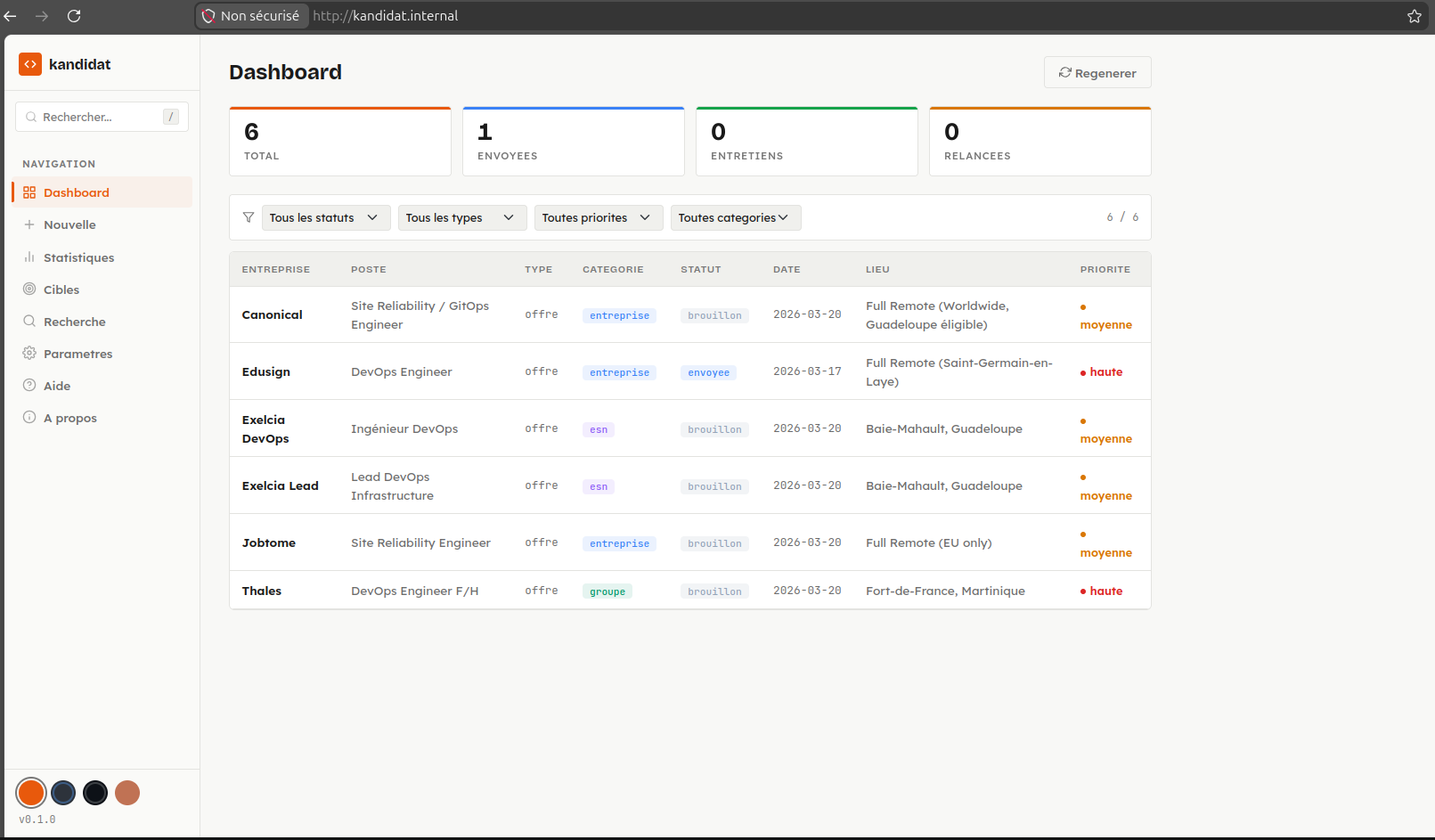
Kandidat est une application web locale de suivi de candidatures. Pas de SaaS, pas de compte à créer, pas de dépendance à un service tiers. Les données restent chez moi, dans une base SQLite en dev ou PostgreSQL en production.
Gestion des candidatures
- Dashboard avec tableau filtrable et triable (statut, type, priorité, catégorie)
- Fiche détaillée par candidature : métadonnées, historique des statuts, contenu en Markdown, fichiers joints
- Machine à états pour les transitions de statut : brouillon → envoyée → relancée → entretien → acceptée/refusée → archivée
- Pièces jointes : CV, lettres de motivation, offres, notes
Entreprises cibles et contacts
- Gestion d’un vivier d’entreprises classées par catégorie (grands groupes, ESN, cabinets de recrutement, associations)
- Fiches contacts associées (nom, rôle, email, téléphone, LinkedIn)
- Réordonnancement par glisser-déposer
- Enrichissement automatique via recherche web (Tavily) + extraction LLM
Adaptation du CV par IA
C’est la fonctionnalité qui m’a le plus motivé. À partir d’un CV de référence en HTML, Kandidat génère une version adaptée au poste et à l’entreprise visée. Le système utilise un provider LLM interchangeable — Claude (via l’API Anthropic) ou Ollama (en local) — pour reformuler et réorganiser le contenu en fonction du contexte.
Le CV adapté peut ensuite être exporté en PDF (via WeasyPrint) ou en DOCX (via python-docx), en conservant une structure ATS-friendly.
Recherche et statistiques
- Recherche full-text hybride (base de données + fichiers Markdown sur disque)
- Tableau de bord analytique : répartition par statut, type, priorité, catégorie d’entreprise
L’architecture technique
Le projet suit une architecture en couches classique, volontairement simple et lisible :
Frontend (Jinja2 + Vanilla CSS/JS)
│
APIFlask (routes HTML + API REST)
│
Services (logique métier, Pydantic)
│
SQLAlchemy (SQLite dev / PostgreSQL prod)Stack backend
- APIFlask (Flask enrichi avec OpenAPI/Swagger auto-généré)
- SQLAlchemy pour l’ORM, Pydantic pour la validation
- WeasyPrint + python-docx pour la génération de documents
- httpx pour les appels HTTP (Ollama, Tavily)
- Provider LLM abstrait via un Protocol Python — ajouter un nouveau provider revient à implémenter deux méthodes
Stack frontend
Pas de framework JS. Du Jinja2 côté serveur, du CSS natif avec un système de design à 4 thèmes (Precision, Dim, Dark, Pastel), et du JavaScript vanilla. L’interface est responsive et fonctionnelle, sans surcharge.
Serveur MCP
Kandidat expose aussi un serveur MCP (Model Context Protocol) en TypeScript, avec 22 outils accessibles depuis Claude Desktop ou Claude Code. On peut gérer ses candidatures en langage naturel : créer une candidature, rechercher, adapter un CV, enrichir une entreprise — le tout via un agent LLM connecté à l’API REST.
La culture DevOps appliquée au projet
Construire l’application ne suffisait pas. Je voulais la traiter comme un vrai produit : qualité de code, tests, sécurité, déploiement automatisé. Pas par formalisme, mais parce que c’est comme ça que je travaille.
Qualité de code
- Ruff pour le linting et le formatage
- Bandit pour l’analyse de sécurité
- pytest avec 81% de couverture
- Pre-commit hooks pour garantir la qualité à chaque commit
Documentation et traçabilité des choix
Un produit sans documentation, c’est un produit que personne d’autre ne peut reprendre. J’attache une importance particulière à documenter non seulement le comment, mais surtout le pourquoi des choix techniques. Le dépôt contient une documentation structurée :
doc/architecture.md— vue d’ensemble de l’architecture, couches applicatives, schéma de la base de donnéesdoc/deployment.md— infrastructure de production, stratégie de déploiement, configuration réseaudoc/configuration.md— variables d’environnement, paramétrage LLM, options de personnalisationdoc/development.md— guide du développeur, conventions, workflow de contributiondoc/mcp-architecture-proposal.md— proposition d’architecture détaillée du serveur MCP, justification des choix de design
Chaque document explique les décisions prises et leurs motivations. Pourquoi APIFlask plutôt que FastAPI ? Pourquoi un Protocol Python pour l’abstraction LLM ? Pourquoi PostgreSQL en production et SQLite en dev ? Ces réponses sont dans la documentation, pas dans la tête du développeur. C’est une habitude que je considère essentielle dans une approche DevOps : le code raconte le quoi, la documentation raconte le pourquoi.
Pipeline CI/CD (GitLab CI)
Le pipeline comporte 5 étapes :
| Étape | Rôle |
|---|---|
| lint | Vérification du style et du formatage (Ruff) |
| test | Tests unitaires et d’intégration (pytest, SQLite in-memory) |
| security | Analyse de sécurité (Bandit) |
| build | Build Docker multi-stage, push vers le registry |
| deploy | Déploiement via Ansible sur le homelab (porte manuelle) |
Déploiement sur le homelab
Le déploiement cible une VM dockhost sur mon homelab Proxmox. Le processus est entièrement automatisé :
- Le runner GitLab (hébergé sur le bastion) exécute le playbook Ansible
- Ansible pull l’image Docker depuis le registry
- Le conteneur est déployé avec PostgreSQL 17 sur un réseau Docker partagé
- Les données persistent via un volume monté
Développeur → GitLab CI → Bastion (runner) → Ansible → Dockhost (container)Pas de déploiement cloud. Tout tourne sur mon infrastructure locale, gérée comme un vrai environnement de production. Si vous voulez en savoir plus sur cette infrastructure, j’en parle en détail dans mon article sur le homelab.
Infrastructure as Code
Les dépôts GitLab et GitHub sont eux-mêmes gérés par Terraform — configuration du projet, protection de branches, variables CI, tout est versionné.
Le rôle du vibecoding dans ce projet
Kandidat a été développé en grande partie en vibecoding avec Claude Code. L’ensemble du backend Flask — routes, services, modèles SQLAlchemy, schémas Pydantic, machine à états — a été construit en mode conversationnel : je décrivais la fonctionnalité attendue, Claude produisait le code, je testais et j’itérais.
Le vibecoding a été particulièrement efficace sur les parties les plus mécaniques : le CRUD des candidatures et des entreprises, la validation Pydantic, le parsing HTML pour la conversion DOCX, et l’intégration des providers LLM. Le serveur MCP en TypeScript a aussi été largement généré par Claude Code, en s’appuyant sur la documentation du protocole.
Mon rôle a été de concevoir le produit, de définir l’architecture, de valider chaque choix technique, et d’apporter l’expertise DevOps pour le pipeline CI/CD et le déploiement Ansible. L’IA est un support, pas un pilote. Ce qui aurait pris des semaines de développement solo a été réalisé en quelques jours, avec un niveau de couverture de tests et de documentation que je n’aurais probablement pas atteint dans le même délai.
Ce que ce projet m’apporte
Kandidat me sert au quotidien dans ma recherche d’emploi. Mais le construire m’a aussi permis de mettre en pratique, de bout en bout, ce que je fais au quotidien en tant que DevOps : partir d’un besoin, concevoir un produit, le développer avec les bons outils — y compris l’IA —, le tester, le documenter, et l’amener en production sur une infrastructure que je gère moi-même.
Le dépôt est disponible sur GitHub : Kandidat